 PDF(1491 KB)
PDF(1491 KB)
 PDF(1491 KB)
PDF(1491 KB)
PDF(1491 KB)
PDF(1491 KB)
一种优化空天地一体化网络吞吐量算法
 ({{custom_author.role_cn}}), {{javascript:window.custom_author_cn_index++;}}
({{custom_author.role_cn}}), {{javascript:window.custom_author_cn_index++;}}A Throughput Optimization in Space-air-ground Integrated Networks
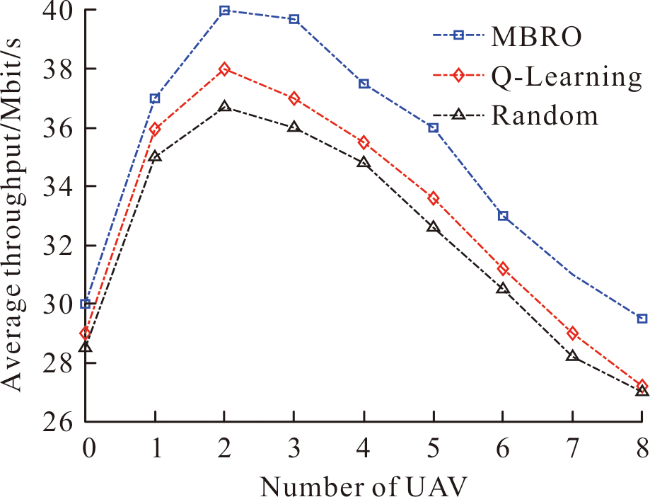
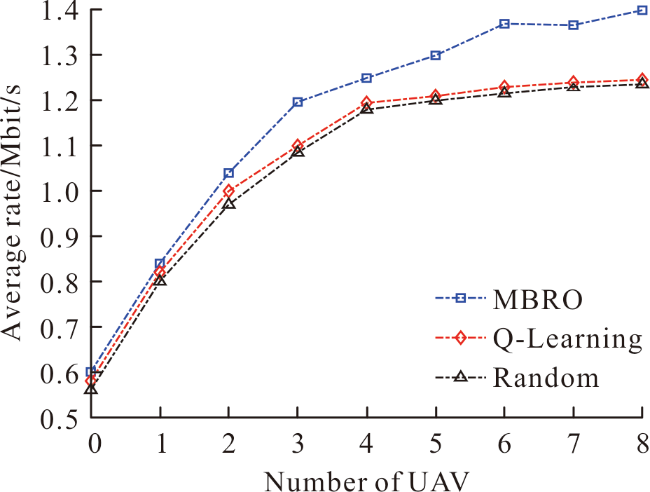
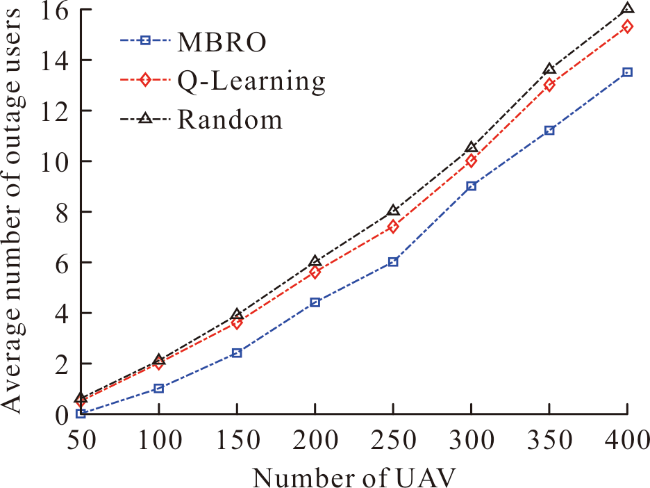
({{custom_author.role_en}}), {{javascript:window.custom_author_en_index++;}}为提高空天地一体化网络的吞吐量,提出基于强化学习的链路优化算法(reinforcement learning-based link optimization, RLLO)。RLLO算法以近地轨道卫星为基站提供回程链路。同时,RLLO算法通过管理无人机和微基站的资源以及优化无人机(unmanned aerial vehicles, UAV)的轨迹,提升吞吐量。先建立优化回程链路和接入链路的目标问题,再利用多臂老虎机的强化学习工具求解目标问题。仿真结果表明,相比于同类的基准算法,RLLO算法提高了吞吐量和用户端的可达速率。
In order to improve throughput of Space-Air-Ground Integrated Networks, Reinforcement Learning-based Link Optimization (RLLO) algorithm is proposed in this paper. In RLLO algorithm, we consider low Earth orbit satellites as an effective backhaul solution. For access links, we manage the radio resource among UAVs and small cell base stations and optimize the trajectories of unmanned Aerial Vehicles in order to improve the throughput. The objective problem of backhaul and access link is constructed. Then, we utilize the tools of reinforcement, and proposed approach based on the multi-armed bandit algorithm. Simulation results show that the proposed RLLO algorithm improve the throughput and rate of user.
空天地一体化网络 / 近地轨道卫星 / 强化学习 / 接入链路 / 多臂老虎机 {{custom_keyword}} /
space-air-ground integrated networks / low earth orbit / reinforcement learning / access link / multi-armed bandit {{custom_keyword}} /
表1 系统仿真参数Table 1 System parameter |
| Parameter | Value |
|---|---|
| Number of satellites | 22 |
| Altitude of satellites/km | 550 |
| Heigh of SBS/m | 15 |
| Height of users/m | 1.5 |
| Carrier frequency/GHz | 28 |
| Channel bandwidth/MHz | 100 |
| wACC/MHz | 56 |
| Noise power spectral density/(dBm/Hz) | -174 |
| Number of SBSs | 6 |
| kb/s | 1 |
| Rmax/s | 1 |
| Ts/s | 1 |
| Toal number ofiterations | 5 740 |
| V/(m/s) | 0~1.3 |
| h/m | 22.5~150 |
| (ϑk/ζk)/(Mbit/s) | 1.8 |
表2 基站的相关参数Table 2 BS parameter |
| Parameter | SBS | UAV | ||
|---|---|---|---|---|
| LoS | NLoS | LoS | NLoS | |
| Path loss exponent | 2 | 2.92 | 2 | 3 |
| Reference path loss | 61.4 | 72 | 61.4 | 61.4 |
| Shadowing standard deviation | 5.8 | 8.7 | 5.8 | 8.7 |
表3 运行时间Table 3 Runtime |
| Algorithm | Runtime/s |
|---|---|
| RLLO | 5.56 |
| Q-Learning | 5.42 |
| Random | 2.36 |
| [1] |
陈晨, 谢珊珊, 张潇潇, 等. 聚合SDN控制的新一代空天地一体化网络架构[J]. 中国电子科学研究院学报, 2015, 10(5): 450-454.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [2] |
何尔利, 纪澎善, 贾向东, 等. 位置协助的无人机毫米波通信网络自适应信道估计[J]. 计算机工程, 2020, 46(6): 202-207.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [3] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [4] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [5] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [6] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [7] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [8] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [9] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [10] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [11] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [12] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [13] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1491 KB)
PDF(1491 KB)
/
| 〈 |
|
〉 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}