 PDF(864 KB)
PDF(864 KB)

Research on Software and Hardware Collaborative Design of Heterogeneous Fusion Processing Module Based on OpenVPX Standard
WEN Minhua, SHI Tianjie, TIAN Jing
JPRMG ›› 2024, Vol. 44 ›› Issue (3) : 103-108.
PDF(864 KB)
PDF(864 KB)
Research on Software and Hardware Collaborative Design of Heterogeneous Fusion Processing Module Based on OpenVPX Standard
 ({{custom_author.role_en}}), {{javascript:window.custom_author_en_index++;}}
({{custom_author.role_en}}), {{javascript:window.custom_author_en_index++;}}With the continuous progress of computer hardware and software technology, the task functions integrated in the airborne computing platform are increasing day by day, resulting in the scale and complexity of the internal computing needs of the platform. In the face of the rapid growth of intelligent applications, the traditional single processor architecture is no longer enough to cope with a variety of complex tasks. Therefore, based on the OpenVPX standard, this study defines and designs a 3U heterogeneous fusion processing module that conforms to the hardware open architecture to meet the needs of a variety of complex tasks. This research also proposes a heterogeneous computing resource pooling technology, which aims to achieve rapid deployment and efficient operation of multi-type task applications, while reducing communication latency, and significantly improving the processing power and applicability of computing platforms. Experimental verification shows that, compared with multi-CPU architecture, the processing time of the heterogeneous fusion processing module designed in this paper is about 4.8 times shorter when executing specific neural network algorithms, which proves that its performance is significantly improved. The results of this study not only demonstrate the significant performance advantages of heterogeneous fusion processing modules in airborne intelligent computing applications, but also provide innovative solutions and technical support for the future development of aviation computing platforms.
airborne computing platform / OpenVPX / hardware open architecture / heterogeneous fusion processing / resource pooling {{custom_keyword}} /
Table 1 Performance comparison between heterogeneous fusion processing system and multi cpu processing system in airborne intelligent computing applications表1 机载智能计算应用下异构融合处理原型与多CPU处理原型系统性能对比 |
| Segment run delay/ms | Total delay (including transfer)/ms | Total power consumption/W | |||
|---|---|---|---|---|---|
| Multi-source data fusion part | Target recognition part | Autonomous decision part | |||
| Heterogeneous fusion Processing prototype | 40.9 | 986.7 | 106.8 | 1 354.2 | 59.4 |
| Multi-CPU Processing prototype | 41.2 | 5 436.8 | 867.4 | 6 545.5 | 63.7 |
| [1] |
阳王东, 王昊天, 张宇峰, 等. 异构混合并行计算综述[J]. 计算科学, 2020, 47(8): 5-16.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [2] |
陈文奎, 陶建义. 美航空电子设备综合化技术发展综述[J]. 外军信息战, 2005(5): 2-5.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [3] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [4] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [5] |
张峰, 翟季冬, 陈政, 等. 面向异构融合处理器的性能分析, 优化及应用综述[J]. 软件学报, 2020, 31(8): 2603-2624.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [6] |
吕相文. 高性能计算云环境下GPU并行计算技术及应用研究[D]. 南京: 南京航空航天大学, 2024.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [7] |
张锦涛, 赵惊涛, 王真理. FPGA与GPU并行计算分析——以Kirchhoff叠前时间偏移为例[J]. 地球物理学进展, 2013, 28(3): 1464-1471.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [8] |
宋奋韬, 王梦莹, 付志远. FPGA发展概论[J]. 科技信息, 2012, (23): 145.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [9] |
李若. Kneron发布全系列低功耗人工智能专用处理器IP[J]. 计算机与网络, 2018, 44(4): 1.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [10] |
李景欣. 基于Vitis的FPGA目标检测算法加速器设计[D]. 大连: 大连理工大学, 2024.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [11] |
孙铭. 嵌入式平台中的PCI Express总线技术研究[D]. 西安: 西安电子科技大学, 2015.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [12] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [13] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [14] |
虞保忠, 郝继锋, 周霆, 等. 云计算应用中的嵌入式容器技术研究[J]. 单片机与嵌入式系统应用, 2021, 21(5): 8-10.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [15] |
敬超, 胡君达, 谭华. 面向CPU/GPU异构服务器集群的节能调度算法[J]. 计算机仿真, 2023, 40(3): 520-528.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(864 KB)
PDF(864 KB)
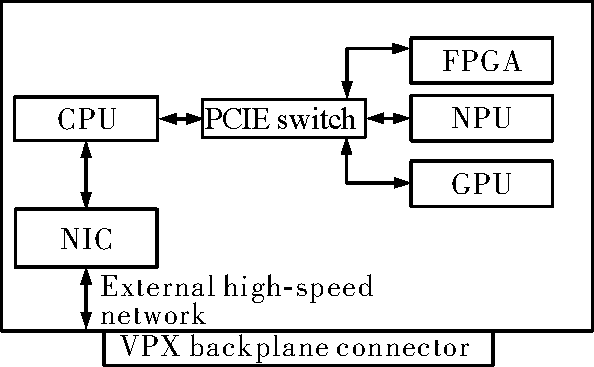
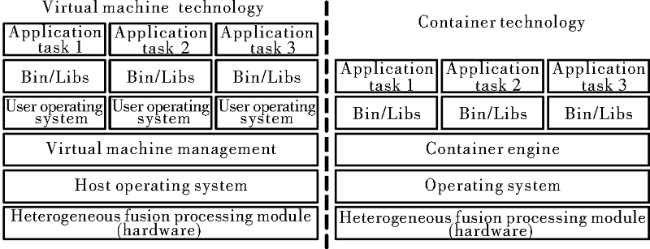
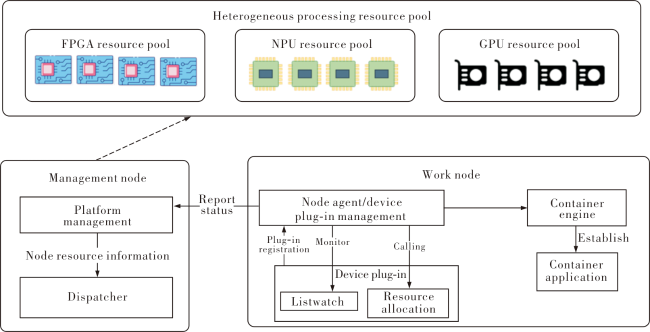
 Fig.1 Hardware architecture diagram of the heterogeneous fusion processing moduleFig.2 Comparison of virtual machine and container computing resource virtualization architecturesFig.3 Heterogeneous processing resource operation and management frameworksFig.4 Heterogeneous processing resource management architecture diagram
Fig.1 Hardware architecture diagram of the heterogeneous fusion processing moduleFig.2 Comparison of virtual machine and container computing resource virtualization architecturesFig.3 Heterogeneous processing resource operation and management frameworksFig.4 Heterogeneous processing resource management architecture diagram Table 1 Performance comparison between heterogeneous fusion processing system and multi cpu processing system in airborne intelligent computing applications
Table 1 Performance comparison between heterogeneous fusion processing system and multi cpu processing system in airborne intelligent computing applications/
| 〈 |
|
〉 |



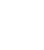

{kind=link}
{kind=link}
{kind=link}
{kind=link}